

[et_pb_section fb_built=”1″ admin_label=”section” _builder_version=”3.22″ fb_built=”1″ _i=”0″ _address=”0″][et_pb_row admin_label=”Reihe” _builder_version=”3.25″ background_size=”initial” background_position=”top_left” background_repeat=”repeat” _i=”0″ _address=”0.0″][et_pb_column type=”4_4″ _builder_version=”3.25″ custom_padding=”|||” _i=”0″ _address=”0.0.0″ custom_padding__hover=”|||”][et_pb_text admin_label=”Text” _builder_version=”3.29.3″ header_font=”Oswald Light||||||||” background_size=”initial” background_position=”top_left” background_repeat=”repeat” hover_enabled=”0″ _i=”0″ _address=”0.0.0.0″]
Warum Server-Side-Daten bessere Daten als Google Analytics-Daten sind
Wenn Sie für einen Publisher arbeiten oder eine Webseite im Allgemeinen verwalten, sind Sie wahrscheinlich mit Google Analytics sehr gut vertraut. Selbst wenn Sie es nicht benutzt haben, sind Sie höchstwahrscheinlich damit in Kontakt gekommen, da es auf 91,93% der Seiten im Internet nahezu universell genutzt wird.
Obwohl Google Analytics eine vollständige Reihe von Metriken kostenlos zur Verfügung stellt, gibt es immer noch einige Einschränkungen innerhalb der Daten auf Skriptebene von GA, und es gibt immer noch häufige Missverständnisse.
Darüber hinaus ist die Ungenauigkeit und die Grenzen der Daten, die mit Google Analytics erfasst werden können, besonders wichtig für Publisher, die zur Generierung von Einnahmen aus Webseiten auf Traffic angewiesen sind.
Heute werde ich Sie durch einige dieser Probleme mit Daten auf Skriptebene führen und Ihnen zeigen, warum serverseitige Daten Ihnen möglicherweise helfen können, sie ganz zu vermeiden. Ich werde auch hervorheben, auf welche Daten Sie auf der serverseitigen Ebene zugreifen können und wie Sie diese Art von Daten kostenlos einsehen können.
Was sind serverseitige Daten auf einer Webseite?
Serverseitige Daten sind genau das, worauf der Name hindeutet: Daten, die auf oder in der Nähe des Servers gesammelt werden. Aber was bedeutet das eigentlich?
Um diese Frage zu beantworten, muss ich zunächst beschreiben, wie ein Internet-Host eine Verbindung zum Internet herstellt. Sie hat eine Internet-Protokoll-Adresse (IP-Adresse). Das DNS (Domain Naming System) ist das System, das hilft, Webseiten wie www.example.com in eine IP-Adresse zu übersetzen, die ein Computer lesen kann: “216.3.128.12”.
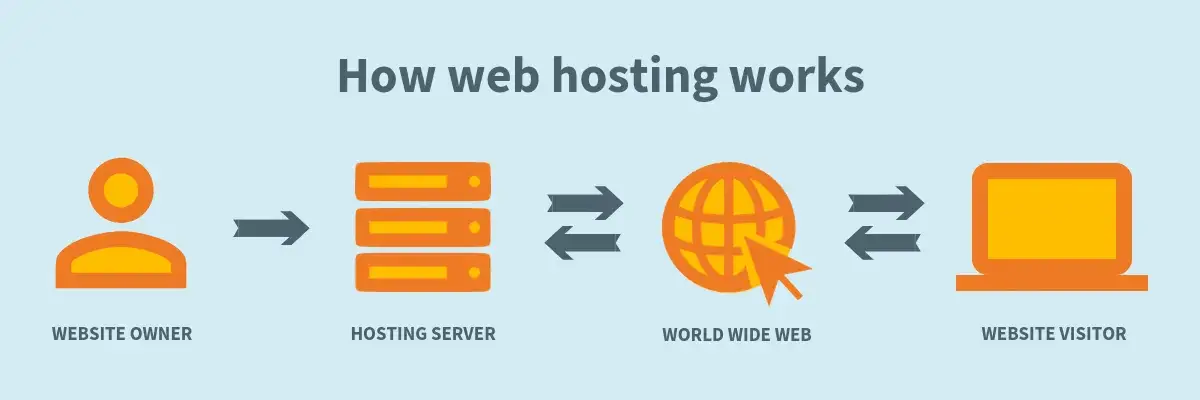
Hier ist eine Übersicht darüber, wie es genau funktioniert.
- Der Web-Browser weiß, dass Sie example.com in die Adressleiste geschrieben haben.
- Ihr Computer verwendet dann DNS, um die aktuellen Name-Server für example.com abzurufen.
- Die öffentlichen Name-Server der Seite; ns1.example.com und ns2.example.com werden abgerufen.
- Ihr Computer fragt unsere Name-Server nach dem Adressdatensatz für example.com.
- Die öffentlichen Name-Server der Seite antworten mit der IP-Adresse 192.144.142.298
- Ihr Computer sendet zusammen mit der von Ihnen angeforderten Seite eine Anfrage an diese IP-Adresse.
- Der Webserver, der example.com hostet, sendet dann Ihrem Webbrowser die angeforderte Seite.
Alle oben genannten Schritte geschehen fast augenblicklich.
Als Publisher zahlen Sie höchstwahrscheinlich für einen Webhosting-Provider (Bluehost, AWS, Host Gator, GoDaddy usw.). Diese Hosts stellen Ihnen einen Server zur Verfügung, damit die Reihe von Dateien, Bildern und HTML-Codes, aus denen Ihre Webseite besteht, online gespeichert werden können.
Serverseitige Daten kommen ins Spiel, wenn Sie ein CDN oder eine andere Technologie in Ihre Seite integrieren, die sich auf Serverebene befindet. Wenn ein Publisher die Name-Server “ns1.example.com und ns2.example.com” einer Webseite auf andere Name-Server als den Host verweist, wird diese Partei zu einem Proxy. Man kann dies als einen Übergabepunkt, Spiegel oder Kanal sehen, den die angeforderte Seite nun durchläuft, wie ein Geist durch eine Wand.
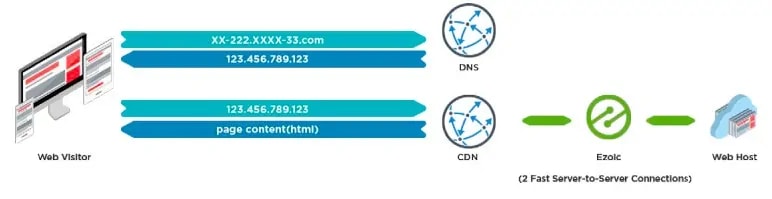
Ezoic’s Technologie, alle CDN’s und andere Technologien, die von den Webseiten der Publisher zwischen dem Webhost und den Anfragen der Webbesucher verwendet werden. Auf diese Weise kann sich der Traffic bei Anfragen schnell bewegen, da keine Seite geladen oder aufgerufen werden muss, um die Anfrage zu ändern oder zu erweitern.
Was ist clientseitig (Skriptdaten), wie Google Analytics?
Die clientseitige Datenerfassung erfolgt in der Regel durch Javascript-“Tags”. Das Javascript wird normalerweise in der Kopfzeile Ihrer Seite platziert, die beim Laden der Seite ausgeführt wird.
Google Analytics ist ein Beispiel für ein Skript oder “Tag”, das Sie auf den Seiten Ihrer Webseite platzieren, um das Besucherverhalten zu verfolgen.
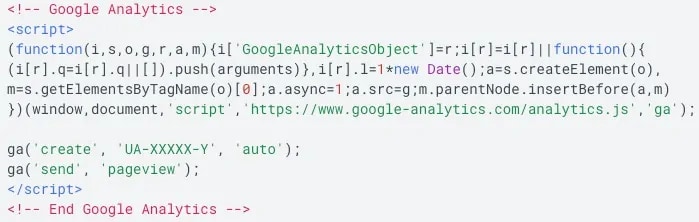
Hinweis: Viele Webseiten verwenden jetzt den Google Tag Manager, anstatt nur Google Analytics hinzuzufügen, so dass Sie anstelle dieses Codes nach dem Code des Google Tag Managers suchen würden.
Wenn ein Besucher eine Seite aufruft und das Core-CSS ausgeführt wird, wird das Google Analytics-Tag des Drittanbieters gemäß den Regeln der Seite ausgeführt, und die Besucherdaten werden gemäß den konkreten Spezifikationen oder Regeln auf dieser Seite verarbeitet (z. B. dürfen DSGVO-konforme Seiten bestimmte Formen von Daten nicht erfassen, bis die Zustimmung zum Cookie erteilt wird).
Außerdem gibt es einige Probleme bei der standardmäßigen Messung der Absprungrate durch GoogleAnalytics, die den Publishern irreführende Daten in Bezug auf die Verweildauer auf der Seite und die Absprungrate liefern können.
Was sind die Vorteile einer clientseitigen Datenerhebung?
Einige der Vorteile und potenziellen Anwendungsfälle von clientseitigen Daten sind:
- Niedrige Kosten, einfaches Setup
- Sie benötigen eine einfache Möglichkeit, Verkäufe oder Konversionen von Leads zu verfolgen
Einige Publisher, die gerade erst anfangen, Datenanalysen zur Überwachung ihrer Seiten einzusetzen, und die die Einfachheit des Einfügens von Tracking-Tags in den Code ihrer Seite mögen, aber clientseitige Daten haben ihre Grenzen.
Warum ist die serverseitige Datenerfassung für Web-Publisher besser?
Die größten Vorteile serverseitiger Daten liegen in Form von Genauigkeit, Detailtiefe und Leistungsmaximierung.
Der zweite Vorteil ist die zusätzliche Sicherheit und das Eigentum an der Datenerhebung. Häufig hassen Publisher die Idee, Google noch mehr Daten und Einblicke in ihre Webseite zu geben, und würden es vorziehen, diese Daten zu verwalten und vor jemandem wie Google geheim zu halten.
Die Daten auf der Server-seitigen Ebene sind in der Lage, alle Attribute einer Nutzeranfrage genauer zu betrachten und können diese in absolut granularer Weise aufzeichnen, ohne dass viele externe Aufrufe oder Seitenverlangsamungen durchgeführt werden müssen, um Dinge zu verfolgen wie:
- Scroll-Tiefe
- Ad Viewability
- Nutzungszeit
- Verbindungsart der Besucher
- Einnahmen-Daten
- Und mehr …
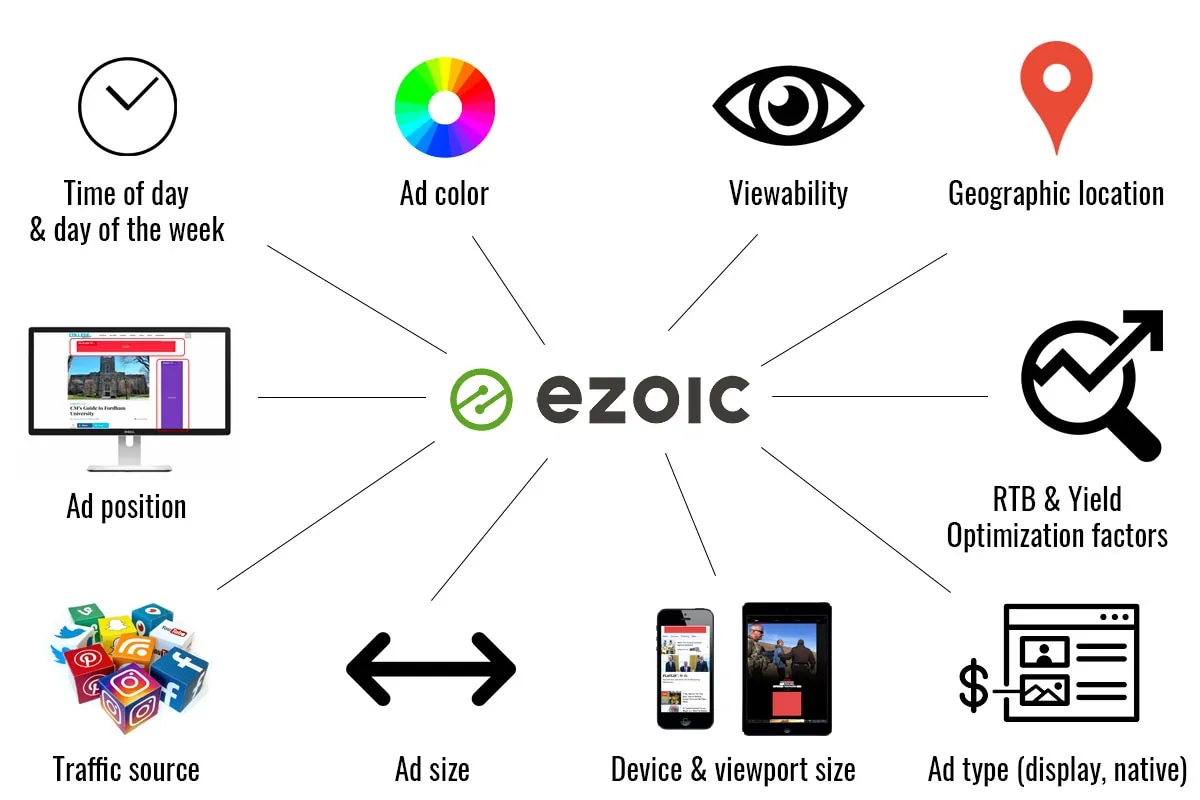
Ezoic’s Big Data Analytics ist ein großartiges Beispiel für ein Tool, das detaillierte Daten liefert, die weit über das hinausgehen, was so etwas wie Google Analytics bietet.
Außerdem verlangsamt es eine Seite nicht auf die Art und Weise, wie dies bei einer Form von Analytics auf Skriptebene der Fall ist.
Ein anhaltender Trend, Daten von Google fernzuhalten
In den Jahren nach Snowden, Cambridge Analytica und mit Datenschutzgesetzen wie DSGVO und CCPA ist der Datenschutz der Verbraucher ein heißes Thema.
Und das aus gutem Grund. Während 2019 das Jahr der Technikgiganten war da sie “Privatsphäre für alle” einschließen, sollten ihre steinigen Geschichten die Menschen ein wenig skeptisch machen, ob diese Aussagen proaktiv oder eher nur reaktiv sind.
Warum ist das wichtig? Nun, einfach ausgedrückt, denn es ist wichtig, an wen Ihre Daten gehen und was mit ihnen gemacht wird. Außerdem sind es Ihre Daten – Publisher entscheiden sich zunehmend dafür, nicht alle ihre Daten an Google weiterzugeben.
Warum ist Datengenauigkeit wichtig?
Als Publisher kann die Genauigkeit Ihrer Datenanalysen die Grenze zwischen dem Verlust von Einnahmen oder dem Auffinden des Datenpunktes sein, der eine neue Inhaltsstrategie auslöst.
Offensichtlich wollen Sie letztere, die die Schaffung von Inhalten und das Wachstum der Einnahmen fördern können.
Mit Google Analytics können Teile Ihrer Seite, die nicht korrekt getaggt sind, zu Datenverlusten beitragen und die Entscheidungsfindung erschweren.
Es gibt sogar einen ausführlichen Artikel zu 29 verschiedenen Google Analytics-Fehlern und wie man sie behebt. Unabhängig davon, wie Sie GA einrichten, handelt es sich immer noch um Daten auf Skriptebene –was bedeutet, dass sie nur als ein Stück Javascript auf Ihrer Seite existiert.
Obwohl es mit Google Tag Manager einfacher ist, den Code mit zusätzlichen Tags anzupassen, weist der Tag Manager immer noch eine Reihe von potenziellen Fehlern auf die eine Menge Zeit in Anspruch nehmen können, um diese selbst zu beheben. Einige große Unternehmen benötigen sogar einen Spezialisten, um Google Analytics ordnungsgemäß einzurichten.
Warum ist die Genauigkeit der Absprungsrate wichtig?
Die Genauigkeit der Absprungsrate spielt eine wichtige Rolle, denn wenn sie künstlich niedrig ist, sollten Sie das Problem angehen. Wenn Ihre Seite durchgehend eine Absprungsrate im Bereich von 60-80% aufweist und diese plötzlich auf einstellige Zahlen abfällt, ist wahrscheinlich etwas mit dem Setup des/der Google Analytics-Tag(s) nicht in Ordnung.
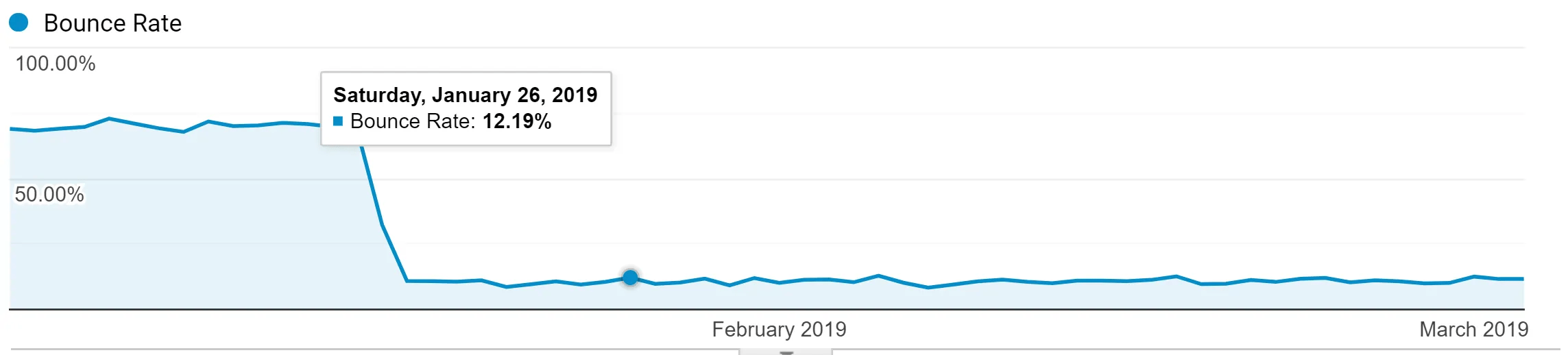
Wenn die Absprungsrate aufgrund von Nutzererlebnissen allmählich sinkt, sollten Sie einen Anstieg bei Dingen wie Nutzungszeit, Zeit auf der Seite und Scrolltiefe feststellen. Möglicherweise werden auch die Einnahmen steigen.
Was ist eine ideale Absprungsrate?
Die Absprungsrate ist relativ zu jeder Seite. Sie sollten sich fragen: “Was sind meine Landing Pages, und was sind meine Erfahrungen auf diesen Seiten?
Oftmals sind Publisher von Absprungsraten besessen. Es könnte nicht alberner sein, sich darüber Sorgen zu machen.
Absprungsraten sind relativ zu jedem Publisher. Darüber hinaus geht es Ihnen vor allem darum, wie Sie sie verfolgen. Sie sind von etwas besessen, das Sie wählen, um sich selbst zu messen. Diese Absprungsrate ist allen anderen unbekannt.
Selbst die Google-Suche schaut nicht direkt auf die Absprungsrate der Webseite. Es wird oft spekuliert, dass Google die Beziehung zwischen einem Besucher und der Ergebnisseite und der Seite, auf die er klickt, misst. Das bedeutet, dass ein Klick auf ein Ergebnis und dann die Rückkehr zur Ergebnisseite und das, was sie als nächstes tun, wahrscheinlich die Messung ist, die am meisten mit der Absprungsrate korreliert.
Eine ideale Absprungsrate gibt es nicht.. Die Wahrheit ist, dass sie von Seite zu Seite variiert, vor allem aber durch die Art der Seite.
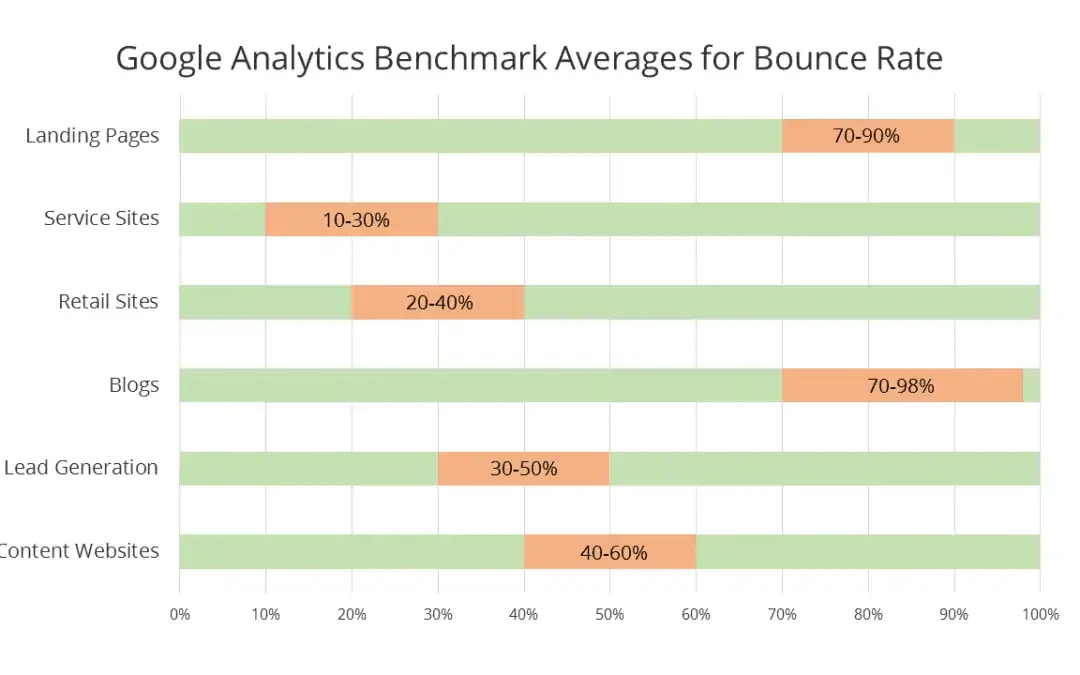
Sie können sehen, dass eine erfolgreiche Einzelhandelsseite eine Absprungsrate von 30% haben kann, während ein erfolgreicher Blog eine Absprungsrate von 75% haben kann. Warum dieser Unterschied?
Das setzt voraus, dass sie alle auf die gleiche Weise die Absprungsrate messen und genau die gleichen Besucher haben… was sie nicht haben und werden!
Ist die Absprungsrate innerhalb von Google Analytics korrekt?
Wenn es richtig eingerichtet ist, dann ja. Aber jede Analytics-Software hat ihre Grenzen. Eine häufige Support-Frage für Nutzer von Ezoic Big Data Analytics lautet: “Warum ist meine Absprungsrate anders als die von Google Analytics?“
Die schnelle Antwort ist, dass das Standardverhalten von Google bei der Nachverfolgung leider grundlegend fehlerhaft ist und aktive Nutzer der Seite “im Moment” nicht genau widerspiegelt.
- Google berechnet diese Zahl als die Anzahl der Nutzer, die die Seite in den letzten 5 Minuten besucht haben.
- In ähnlicher Weise berechnet Ezoic die Zahl “im Moment” für jeden Nutzer, der in den letzten 5 Minuten “einige” Aktivitäten hatte.
Bsp: Nehmen wir an, ein Besucher kommt auf Ihre Seite und findet einen großartigen, langen Artikel mit vielen interessanten Inhalten, und es dauert etwa fünfzehn Minuten, um den gesamten Beitrag zu lesen. Nach der Definition von Google würden sie diesen Nutzer nach den ersten 5 Minuten als inaktiv einstufen.
Einer der Vorteile von Big Data Analytics ist, dass unsere Definition diesen Besuch in Echtzeit berücksichtigt. Das System weiß, dass der Nutzer aktiv ist, weil der Nutzer scrollt und den Inhalt ggf. kopiert/einfügt. Aufgrund dieses Unterschieds werden Publisher in Big Data Analytics-Reports im Vergleich zu Google Analytics wahrscheinlich eine niedrigere Anzahl sehen.
Big Data Analytics verfolgt einen Absprung, wenn jemand das, wofür er von einer Webseite gekommen ist, nicht bekommt (verlässt die Webseite in weniger als 30 Sekunden, kopiert und fügt nichts ein, scrollt nicht bis zum Ende der Seite). Das einfache Verlassen nach einem Seitenaufruf sollte für die meisten Publisher nicht als “Bounce” angesehen werden.
Warum die Kopplung von Werbeeinnahmen an serverseitige Daten sehr hilfreich ist
Die Bindung der Einnahmen an Analytics ist wichtig, weil sie Ihre Entscheidungsfindung beeinflussen kann. Es kann Ihnen sagen, was Sie falsch und was Sie richtig machen, und Ihnen ermöglichen, sich entsprechend anzupassen.

Wenn Sie Ihre Daten zu den Einnahmen aus Anzeigen in Google Analytics verknüpfen möchten, kostet Sie das satte 150.000 US-Dollar für Google Analytics 360 (und erlaubt Ihnen immer noch nicht die Berücksichtigung von Anzeigenbedarfsquellen außerhalb von AdX oder AdSense).
Bei einem so hohen Preis könnten in der Regel nur große Publisher dieses Produkt für die Segmentierung der Zielgruppen hilfreich finden.
Eines der besten Dinge an serverseitigen Daten, die alle Einnahmequellen auf der Seite anzeigen können, ist, dass Sie sehen können, wie die Einnahmen an alles gebunden sind.. Selbst wenn Sie es mit AdSense tun, erhalten Sie nicht dieselbe Art von Detailgenauigkeit – Sie können sehen, wie sich alles auf alles auswirkt.
- Autorenmetriken
- Kategorien
- Geographische Informationen
- Einnahmen nach Landing Pages
- Nach Gerätetyp
- Andere Anzeigen und ihre Auswirkungen auf andere Anzeigenwerte
- Und mehr
Ein gutes Beispiel für die Art von Detailliertheit, von der ich spreche, ist die effektive Verwendung von Kategorien, wobei diese Daten auch an Einnahmen gebunden sind.
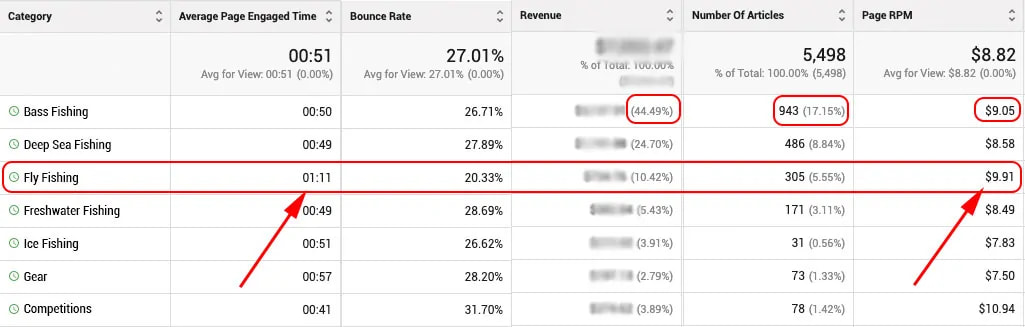
Sie können oben sehen, dass “Barschfischen” 44,49% der gesamten Einnahmen der Seite ausmacht und auch den höchsten Prozentsatz der erstellten Artikel ausmacht (17,15%).
Aber wenn Sie sich den EPMV nach Artikelkategorie ansehen, sehen Sie, dass “Fliegenfischen” von allen Kategorien bei weitem den höchsten EPMV hat. Hinzu kommt, dass die “durchschnittliche Seitennutzungsszeit” mit 1 Minute und 11 Sekunden gut 20 Sekunden länger ist als die Mehrzahl der anderen Kategorien.
Diese Art von kategorialen Daten, die an Einnahmen gebunden sind, können Ihre aktuelle und zukünftige Inhaltsstrategie beeinflussen.
Ein Vorbehalt gegenüber der zukünftigen GA könnte nicht so wirksam sein, wenn mehr Webseiten und Browser anfangen, Skripte von Drittanbietern auszuschließen, weil es nicht lokal auf der Seite liegt, auf der die Daten physisch gesammelt werden.
Warum Sie serverseitige Daten verwenden sollten, wenn Sie können
Während es Vor- und Nachteile sowohl der server- als auch der clientseitigen Datenerfassung gibt, bieten serverseitige Daten speziell für Publisher eine detailliertere und genauere Form von Analytics. Bei der Mehrzahl der serverseitigen Datenerfassung können Sie die clientseitige oder skriptbasierte Datenerfassung wie Google Analytics ohnehin in Ihre Seite integrieren, wenn Sie es vorziehen, eine Kombination aus beidem zu verwenden.
Für Publisher, die eine größere Detailgenauigkeit ihrer Daten, mehr Sicherheit und eine schnellere serverseitige Datenerfassung wünschen, ist dies der beste Weg, wenn sie sich entscheiden müssen.
Haben Sie Fragen zu server- oder clientseitigen Daten? Lassen Sie es mich in den Kommentaren wissen, und ich werde mein Bestes tun, um darauf zu antworten.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]